
1. 알고리즘
- 백준 2251번
2. 운영체제(공룡책)
*챕터1
1.4 자원 관리
운영체제는 자원(CPU, 메모리 공간, 파일-저장공간, I/O장치) 관리자이다.
1.5.1 프로세스 관리(Process Management)
프로세스란 실행 중인 프로그램을 의미한다. 프로세스는 자신의 일을 수행하기 위해 자원을 필요로 하고 이러한 자원들은 프로세스가 실행 상태일 때 할당 된다. 프로세스가 종료되면 운영체제는 재사용 가능한 자원을 회수한다.
하나의 프로그램은 디스크에 저장된 파일의 내용과 같이 수동적(passive) 개체지만, 프로세스는 다음 수행할 명령을 지정하는 프로그램 카운터를 가진 능동적(active)인 개체다. CPU는 프로세스의 명령들을 차례대로 수행한다. CPU는 한번에 하나의 프로세스만 실행 가능하다. 멀티스레드 프로세스는 여러개의 프로그램 카운터를 가지고 있으며 이 카운터들은 각 스레드가 실행할 다음 명령어를 가리킨다. 모든 프로세스는 단일 CPU코어에서 멀티플렉싱하거나 여러 CPU코어에서 병렬로 실행 할 수 있다.
운영체제의 프로세스 관리
- 사용자, 시스템 프로세스들의 생성 및 제거
- CPU스케줄링을 통한 프로세스, 스레드 실행순서 관리
- 프로세스의 일시 중지 및 재수행
- 프로세스 동기화를 위한 기법 제공 - 세마포어, 뮤텍스, 모니터 등
- 프로세스 통신을 위한 기법 제공
* 멀티 플렉싱(Multiplexing) : 네트워크에서 주로 사용되는 용어이나 해당 문단에선 여러 개를 하나로 묶어 다중화 시키는 개념으로 쓰인듯하다.
1.5.2 메모리 관리 (Memory Management)
메인 메모리는 현대 컴퓨터 시스템의 작동에 중추적인 역할을 한다. 주 기능은 CPU와 입출력 장치에 의하여 공유되는, 빠른 접근이 가능한 저장소 역할이다. 메인 메모리는 CPU가 직접 주소를 지정할 수 있고, 직접 접근할 수 있는 유일한 대량 메모리이다. 예를들어 보조저장장치에 있는 데이터를 읽거나 쓰거나 실행등을 하려면 먼저 메인메모리로 가져와야 한다.
프로그램이 수행되기 위해서는 반드시 절대 주소로 mapping되고 메모리에 적재되어야 한다. 이러한 절대 주소를 통해 cpu는 메모리의 프로그램 명령어와 데이터에 접근할 수 있다. 프로그램이 종료되면 프로그램이 적재되어 있던 메모리 공간은 가용 공간이 되고 다른 프로그램이 적재되어 실행 될 수 있다.
CPU이용률과 사용자에 대한 컴퓨터의 응답속도 개선을 위해선 메모리에 여러개의 프로그램을 적재할 수 있어야 한다. 적재되는 프로그램들을 유지하려면 메모리 관리기법이 필요하다. 여러 메모리 기법 중 어떤 것을 선택할지에 대한 가장 중요한 요인 중 하나는 시스템의 하드웨어 설계와 관련되어 있다.
운영체제의 메모리 관리
- 메모리의 어느 부분이 현재 사용되고 있으며 어느 프로세스에 의해 사용되고 있는지 추적해야 한다.
- 필요에 따라 메모리 공간을 할당하고 회수해야 한다.
- 어떤 프로세스들(전체 또는 일부)을 메모리에 적재하고 제거할 것인가를 결정해야 한다.
1.5.2 파일 시스템 관리 (File-System Management)
파일이란 운영체제가 저장장치의 물리적 특성을 추상화하여 논리적인 저장단위로 만든 것이다. 운영체제는 파일을 물리적으로 매핑하며, 저장장치를 통해 파일들에게 접근한다. 파일은 프로그램(소스와 목적프로그램 형태)과 데이터를 나타낸다.
운영체제는 대량 저장 매체와 그것의 장치 관리자를 제어 함으로써 파일의 추상적인 개념을 구현한다. 또한 파일은 사용하기 쉽도록 통상 디렉터리들로 구성된다. 다수의 사용자에 의해 파일이 접근 될 때는 누구, 어떤 방법으로 파일이 접근되어야하는가를 통제하는것이 바람직하다.
운영체제의 파일 시스템 관리
- 파일, 디렉터리의 생성 및 제거
- 파일, 디렉터리 조작을 위한 프리미티브 제공
- 파일을 보조저장장치로 매핑
- 비휘발성 저장매체에 파일을 백업
1.5.2 대용량 저장장치 관리 (Mass-Storage Management)
컴퓨터 시스템은 메인 메모리를 백업하기 위해 보조저장장치를 제공해야 한다. 프로그램 대부분은 보조저장장치에 저장되기 때문에 이 장치의 관리는 컴퓨터 시스템에서 가장 중요하다.
보조저장장치는 매우 빈번하고 폭넓게 사용되므로 컴퓨터의 전체 동작속도에 영향을 끼친다. 그러므로 서브시스템과 그것을 조작하는 알고리즘의 효율성이 중요하다.
운영체제의 대용량 저장장치 관리
- 마운팅, 언마운팅(운영체제가 장치를 인식,해제 하는 기능)
- 가용 공간(free-space)의 관리
- 저장장소 할당
- 디스크 스케줄링
- 저장장치 분할(partitioning)
- 보호
1.5.2 캐시 관리 (Cache Management)
데이터는 통상 어떤 저장장치에 보관된다. 데이터가 필요함에 따라, 더 빠른 장치인 캐시에 일시적으로 복사된다. 특정 데이터가 필요한 경우, CPU는 캐시에 해당 데이터가 있는지 먼저 확인한다. 있는 경우엔 캐시히트 없는 경우엔 캐시미스라고 하며 메모리에 접근해야 한다. 이 때 이 데이터가 곧 다시 사용될 확률이 높다는 가정하에 캐시에 넣는다.(지역성때문)
CPU내부의 프로그램 가능한 레지스터들은 메인 메모리를 위한 고속의 캐시로 볼 수 있다. 프로그래머(또는 컴파일러)는 어느 정보를 메인 메모리에 두고, 어느 정보를 레지스터에 둘 것인지를 결정하는 레지스터 할당 정책과 교체 알고리즘을 구현해야 한다. 전적으로 하드웨어로 구현된 캐시도 있다.
캐시는 속도는 빠르지만 용량이 작은 한계를 가지기 때문에 캐시관리는 중요한 설계문제다. 저장장치의 계층 구조에서 각 수준간의 데이터 이동은 하드웨어 설계나 제어하는 운영체제에 따라 명시적 또는 묵시적으로 이루어진다.

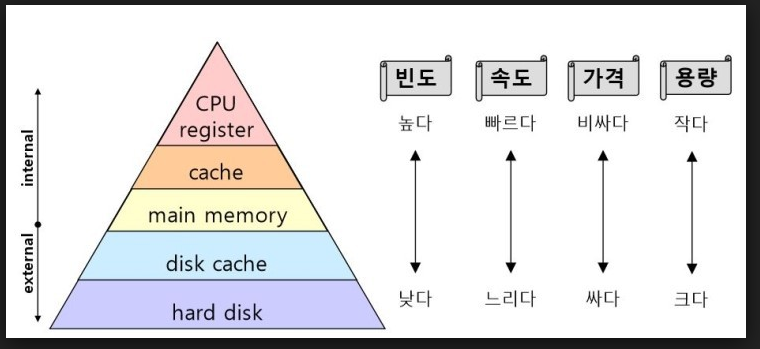
데이터는 여러 저장장치를 거치면서 이동한다. 이 때 CPU연산을 통해 데이터가 바뀌면 여러 저장장치에서 해당 데이터의 값이 달라진다. 여러 저장장치에서 해당 데이터의 값은 자기디스크(보조저장장치)에 새로운 데이터의 값을 다시 기록한 후에야 같아 진다.
어떤 시간에 오직 하나의 프로세스만 실행하는 환경에선 윗 문단과 같은 기법이 문제가 없다. 항상 계층 구조의 최상위 값을 참조하기 때문이다. 그러나 CPU가 여러개의 프로세스 사이에서 계속 전환되는 다중 태스킹 환경에선, 여러 개의 프로세스들이 해당 데이터에 접근하길 원할 경우 이들 각 프로세스가 가장 최근에 갱신된 데이터의 값을 얻을 것을 보장하기 위해선 극도의 주의가 필요하다.
이러한 문제는 분산환경에선 더욱 복잡해진다. 여러 복제본이 동시에 엑세스하여 업데이트 할 수 있으므로 일부 분산시스템은 복제본을 한 곳에서 업데이트 할 때 다른 모든 복제본을 가능한 빨리 최신 상태로 유지하는 것을 보장한다.
캐시 : 데이터나 값을 미리 복사해 놓는 임시장소. 메모리가 CPU보다 속도가 느리기에 매번 접근하는것은 성능을 저하시키기 때문에 캐시라는 완충지대를 사용한다.
캐시 일관성 문제 : 데이터의 변경에 따라 모든 캐시에 즉각적으로 반영되어야 한다. -> 일반적으로 하드웨어적 문제
1.5.6 입출력 시스템 관리(I/O Systems Management)
운영체제의 목적 중 하나는 사용자에게 특정 하드웨어 장치의 특성을 숨기는 것이다. 단지 장치 드라이버만이 자신에게 지정된 특정 장치의 특성을 알고있다.
운영체제의 입출력 관리
- 버퍼링, 캐싱, 스풀링을 포함한 메모리 관리 구성요소
- 일반적인 장치 드라이버 인터페이스
- 특정 하드웨어 장치들을 위한 드라이버
3. 후니의 쉽게 쓴 시스코 네트워킹
* Part4
Section 2
허브 : 이더넷 네트워크에서 여러 대의 컴퓨터, 네트워크 장비를 연결하는 장치
- 구멍의 개수에 따라 몇 포트 허브냐로 나눔
- 허브는 서로 연결하게 되면 1대의 허브처럼 작동
- 같은 허브에 연결된 PC끼리는 서로 통신 가능
- 주요 기능은 리피터의 역할 -> 중간에서 들어온 데이터를 다른 쪽으로 전달해 주는 역할
- 이더넷 네트워크에서 운용되기 때문에 CSMA/CD의 적용을 받음 -> 콜리전 발생 가능성
- 같은 허브에 있는 모든 PC들은 Collision Domain에 있다
Section 3
Collision Domain에 있는 PC들은 한 PC만 데이터를 전송할 수 있고 이러한 기능을 수행하는 허브를 Shared Hub라고 한다. 따라서 10Mbps의 허브에 20대의 PC를 연결해서 쓴다면 10/20Mbps의 속도로 운용된다. 적은 트래픽일 경우 문제가 되지 않지만 트래픽이 많은 경우엔 문제가 된다. 또 한 번의 콜리전이 발생하면 다른 모든 PC들에게 영향이 간다.
Section 4
Intelligent hub : NMS(Network Manage System)을 통해서 관리가 되는 허브 <-> Dummy hub
- 문제가 생긴 PC를 Isolation(고립)시켜 해당 포트를 방출한다. -> 다른 PC에 영향X
- 분리된 포트는 램프로 표시되기 때문에 인지하기 쉽다. -> Auto Partition이라 불림(Dummy에도 있음)
semi dummy hub : 더미 허브인데 인텔리전트 허브와 연결하면 자신도 인텔리전트 허브가 되는 허브
Stackable hub : 스택이 가능한 허브
- Backplane이 훨씬 빨라지고, 장비 하나가 고장나도 다른 장비에 영향x
- 단독형(Stand alone)을 여러대 사용 할 때 보다 훨씬 효율적
4. 김영한의 Spring 로드맵
- Maven과 gradle은 라이브러리 추가를 용이하게 만들어 줌(예를 들어 A->B->C의 의존 관계를 지닌 라이브러리가 있을 경우 C를 추가하면 A,B가 같이 자동으로 추가되게 만듬)
- spring-boot-stater-logging --> logback, slf4j 라이브러리(로그확인용 라이브러리)
- spring.io -> spring 공식문서 확인
- thymeleaf.org -> thymeleaf 공식문서 확인
- 웹브라우저에 도메인주소를 입력하면 톰캣 서버를 통해 스프링컨테이너에선 해당 url을 받는 메소드가 controller에 있는지 확인.
- 있을 경우 해당 메소드를 실행하고 데이터를 model에 저장
- 이때 return 값이 templates패키지에 파일로 존재하는 경우 thymeleaf템플릿 엔진과 매핑
'TIL' 카테고리의 다른 글
| TIL - 0315 (0) | 2023.03.15 |
|---|---|
| TIL - 0314 (0) | 2023.03.14 |
| TIL - 0309 (0) | 2023.03.10 |
| TIL - 0308 (0) | 2023.03.08 |
| TIL - 0307 (0) | 2023.03.07 |