
1. 알고리즘
- 미학습
2. 운영체제(공룡책)
*챕터1
1.2.3 입출력 구조(I/O Structure)
인터럽트 구동 시 대용량 데이터의 이동은 오버헤드를 야기 시킬 수 있기 때문에 DMA가 사용된다.
DMA(Direct Memory Access) : 직접 메모리 접근. 즉, 특정 하드웨어 하위 시스템이 CPU와 독립적으로 메인 메모리에 접근할 수 있게 해주는 컴퓨터 시스템의 기능
이로 인해 장치 컨트롤러가 전송 작업을 수행하고 있는 동안 CPU는 다른 작업을 수행할 수 있다.
1.3 컴퓨터 시스템 구조
처리기(Processor) : 연산 수행. CPU
1.3.1 단일 처리기 시스템(Single-Processor Systems)
하나의 CPU로 작업을 처리
전용 마이크로 프로세서
- 다른 특수 목적 프로세서를 가질 수 있다. -> 디스크, 키보드 및 그래픽 컨트롤러 같은 장치별 프로세서 형태
이러한 전용 처리기들은 운영체제와 통신하지 않고 독립적으로 작업을 처리한다.
즉, 범용 CPU가 하나만 있고 그외 특정 장치를 컨트롤 하기 위한 프로세서들이 여러개 존재
1.3.2 다중 처리기 시스템(Multiprocessor Systems)
2개 이상의 CPU로 작업을 처리
단일 시스템에 비해 데이터 처리량이 증가하는 것이 장점이다. 단 CPU 개수 증가와 처리량은 비례하지 않는다.
- 오버헤드와 공유자원에 대한 경합으로 프로세서의 예상 이득을 낮춤
SMP(Symmetric Multi-Processing) : 대칭형 다중 처리기. 가장 일반적인 형태의 다중 처리기 시스템

- 그림에서 보듯 각각의 프로세서(CPU)들은 독립적으로 구성되며 시스템 버스를 통해 메인 메모리를 공유한다.
- 한번에 한개의 프로세서만이 동일한 메모리에 접근 가능하기 때문에 메모리로부터 읽는 작업에 상당한 시간을 소모
- 프로세서간 작업 부하 분산에 용이
다중 코어 시스템 : 하나의 칩에 여러개의 컴퓨팅 코어를 가지는 것
다중 코어 시스템은 칩 내에서 통신을 하기에 칩 간 통신을 하는 단일 코어 여러개 보다 훨씬 더 적은 전력을 사용한다.
또 다중 코어 프로세서는 운영체제에게 n개의 CPU로 인식된다.
NUMA(non-uniform memory access) : 불균일 기억장치 접근. 각각의 프로세서에 독립적인 별도의 메모리(로컬메모리)를 제공해 성능 충돌을 해결
- 더 많은 프로세서가 추가될 수록 더 효과적으로 확장 가능
- CPU가 시스템 상호 연결을 통해 원격 메모리에 액세스해야 할 때 지연시간이 증가해 성능 저하가 발생
블레이드 서버 : 다수의 처리기, 입출력, 네트워킹 보드들이 하나의 섀시(chassis)안에 장착되어 물리 공간 및 에너지 이용을 최소화하는 데 최적화된 모듈러 설계를 갖춘 서버(고밀도 서버)
- 일반적인 다중 처리기시 시스템과 다른 점은 블레이드-처리기 보드는 독립적인 부팅이 가능하고 자신의 운영체제를 수행한다는 것이다.
- 근본적으로 블레이드 서버는 여러 독립적인 다중 처리기 시스템으로 구성된다.
1.3.3 클러스터형 시스템(Clustered Systems)
여러 CPU를 가진 시스템의 또 다른 유형
둘 이상의 독자적 시스템 또는 노드(다중 코어 시스템)들을 연결하여 구성
클러스터 컴퓨터는 저장장치를 공유하고 LAN이나 InfiniBand와 같은 고속의 상호 연결망으로 연결 된다.
컴퓨팅 노드들은 클러스터 미들웨어라는 소프트웨어 계층에서 관리되며, 각 노드들의 상부층에 위치해 사용자들이 단일 시스템의 개념으로 하나의 커다란 컴퓨팅 단위로 처리할 수 있도록한다.
일반적인 다중 처리기 시스템과 다른 점은 여러 코어를 연결하는 것이 아닌 하나의 rack장비에 독자적인 여러 컴퓨터를 연결하여 작동한다는 것이다.
그리고 이러한 rack 장비들이 모여 하나의 시스템을 구성한다.
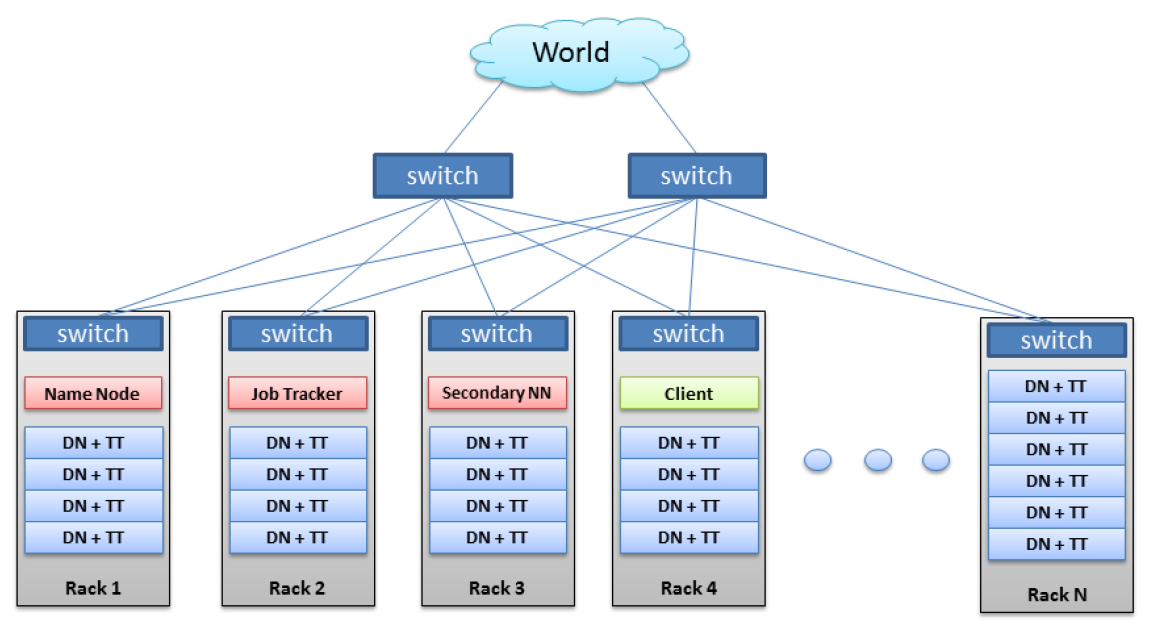
클러스터링은 통상적으로 높은 가용성을 제공하기 위해 사용된다. 즉, 클러스터 내 하나 이상의 컴퓨터 시스템이 고장나더라도 서비스는 계속 제공된다는 뜻이다.
우아한 성능저하(graceful degaradation) : 남아있는 하드웨어 수준에 비례해 서비스를 계속 제공하는 기능
결함허용 시스템 : 일부 시스템이 정상적인 성능 저하를 넘어 단일 구성요소에 오류가 발생해도 계속 작동 가능
비대칭형 클러스터링 : 다른 컴퓨터들이 응용 프로그램을 실행할 동안 한 컴퓨터는 긴급 대기(hot-standby)모드 상태유지
- 대기 상태의 컴퓨터는 활성 서버들을 감시하고 고장날 경우 대신 활성 서버가 된다.
대칭형 클러스터링 : 둘 이상의 호스트들이 응용프로그램을 실행하고 서로를 감시하는 구조
- 가용한 하드웨어를 모두 사용하기 때문에 더 효율적
- 대칭형이 효율적으로 동작하기 위해선 하나 이상의 응용프로그램이 실행 가능해야 한다.
클러스터내의 모든 컴퓨터에서 응용프로그램을 병렬 수행할 수 있으므로 단일처리기나 SMP시스템보다 훨씬 큰 계산능력을 제공한다. 그렇지만 응용프로그램에 따라 작업 부하를 분산하는 방식은 크게 다를 수 있다.
병렬 클러스터와 WAN을 이용한 클러스터링
병렬 클러스터 : 여러 호스트가 공유 저장장치상의 동일한 데이터에 접근할 수 있게 한다.
- 단, 데이터에 대한 공유 접근간의 충돌이 발생하지 않는 것을 보장하기 위하여 접근 제어와 잠금기법을 제공해야한다.
분산 잠금관리자(distributed lock manager-DLM)가 해당 기법을 구현하고 이러한 기능은 몇몇의 클러스터 기술에 포함되어 있다.
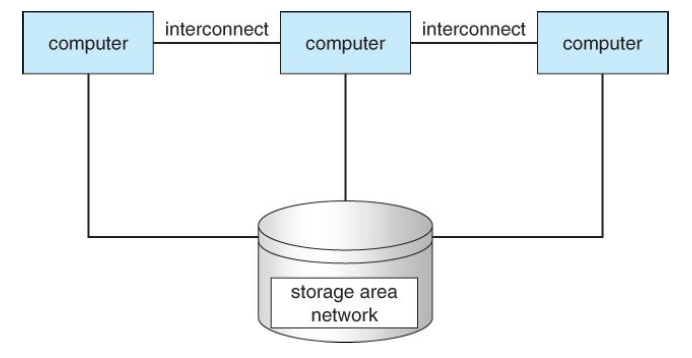
SAN에 의해 어떤 클러스터 제품은 수 킬로미터 떨어진 클러스터 노드뿐 아니라 한 클러스터안에 수천개의 노드를 지원할 수 있게 됐다. SAN은 여러 호스트를 여러 저장장치에 부착할 수 있게 한다.
3. 후니의 쉽게 쓴 시스코 네트워킹
* Part2
Section 7
유니 캐스트 : 1대1통신, CPU성능 저하 X -> 자신의 주소가 아니면 랜카드가 프레임을 버리기 때문
브로드 캐스트 : 1대 다 통신(브로드캐스트 도메인내 모두), FFFF.FFFF.FFFF(MAC주소)로 주소가 미리 정해져 있다.
패킷을 받은 모든 노드는 이 패킷을 CPU로 전송하기 때문에 CPU성능 저하가 발생한다.
멀티 캐스트 : 브로드 캐스트의 단점을 보완해 선택적으로 다수의 노드에게 패킷을 전송. 단, 라우터나 스위치에서 해당 기능을 지원해줘야한다.
Section 8
OSI 7 Layer의 탄생 이유
1. 데이터의 흐름 파악 용이
2. 문제 해결 용이
3. 여러 회사의 장비를 써도 네트워크 상태 이상 없음
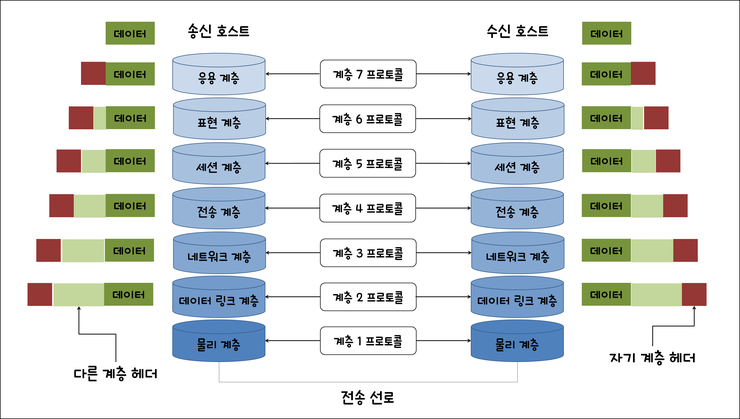
위 그림에서 보듯 아래 계층으로 내려가며 '헤더'가 붙는다. 헤더에는 각 계층별로 관리하는 여러가지 사항들에 대한 정보가 저장되어 있다.
Section 9
프로토콜 : 규약, 협약 -> 컴퓨터 간에 통신하기 위해서 꼭 필요한 상호간의 통신 규약
대표적으로 TCP/IP(Transmission Control / Internet), AppleTalk(매킨토시), IPX, NetBEUI가 있다.
* Part3
Section 1
TCP/IP의 가장 큰 특징은 각각의 네트워크에 접속하는 호스트들은 고유주소를 가지고 있어서 자신이 속해 있는 네트워크뿐만 아니라 다른 네트워크에 연결되어 있는 호스트까지도 서로 데이터를 주고 받을 수 있도록 만들어져 있는 것이다.
Section 2
IP주소는 고유하다. IPv4에서 주소 고갈 문제는 NAT, PAT같은 해결 방식을 가지고 있다.
4. 김영한의 Spring 로드맵
- 기본설치. 인텔리제이 무료판이라도 써야하나..
'TIL' 카테고리의 다른 글
| TIL - 0310 (0) | 2023.03.11 |
|---|---|
| TIL - 0309 (0) | 2023.03.10 |
| TIL - 0307 (0) | 2023.03.07 |
| TIL - 0306 (1) | 2023.03.06 |
| TIL - 0304 (0) | 2023.03.04 |